〉 搬运自:https://blog.csdn.net/lianhunqianr1/article/details/124977297
eBPF特性
eBPF程序都是事件驱动的,他们会在内核或者应用程序经过某个确定的Hook点的时候运行,这些Hook点都是提前定义的,包括系统调用、函数进入/退出、内核tracepoints、网络事件等。
如果针对某个特定需求的Hook点不存在,可以通过kprobe或者uprobe来在内核或者用户程序的几乎所有地方挂载eBPF程序。
Verification
每个eBPF程序加载到内核都要经过Verification,用来保证eBPF程序的安全性,主要有:
-
要保证 加载 eBPF 程序的进程有必要的特权级,除非节点开启了 unpriviledged 特性,只有特权级的程序才能够加载 eBPF 程序
-
内核提供了一个配置项 /proc/sys/kernel/unprivileged_bpf_disabled 来禁止非特权用户使用 bpf(2) 系统调用,可以通过 sysctl 命令修改
-
比较特殊的一点是,这个配置项特意设计为一次性开关(one-time kill switch), 这意味着一旦将它设为 1,就没有办法再改为 0 了,除非重启内核
-
一旦设置为 1 之后,只有初始命名空间中有 CAP_SYS_ADMIN 特权的进程才可以调用 bpf(2) 系统调用 。Cilium 启动后也会将这个配置项设为 1:
1$ echo 1 > /proc/sys/kernel/unprivileged_bpf_disabled -
-
要保证 eBPF 程序不会崩溃或者使得系统出故障
-
要保证 eBPF 程序不能陷入死循环,能够 runs to completion
-
要保证 eBPF 程序必须满足系统要求的大小,过大的 eBPF 程序不允许被加载进内核
-
要保证 eBPF 程序的复杂度有限,Verifier 将会评估 eBPF 程序所有可能的执行路径,必须能够在有限时间内完成 eBPF 程序复杂度分析
JIT Compilation
Just-In-Time(JIT)编译用来将通用的eBPF字节码翻译成与机器相关的指令集,从而极大加速BPF程序的执行:
- 与解释器相比,他们可以降低每个指令的开销。
- 减少生成的可执行镜像的大小,因此对CPU的指令缓存更友好
- 特别的,对于CISC指令集(例如x86),JIT做了很多优化,目的是为给定的指令产生可能的最短操作码,以降低程序翻译过程所需要的空间。
64位的 x86_64、arm64、ppc64、s390x、mips64、sparc64 和 32 位的 arm 、x86_32 架构都内置了 in-kernel eBPF JIT 编译器,它们的功能都是一样的,可以用如下方式打开:
|
|
32 位的 mips、ppc 和 sparc 架构目前内置的是一个 cBPF JIT 编译器。这些只有 cBPF JIT 编译器的架构,以及那些甚至完全没有 BPF JIT 编译器的架构,需要通过内核中的解释器(in-kernel interpreter)执行 eBPF 程序。
要判断哪些平台支持 eBPF JIT,可以在内核源文件中 grep HAVE_EBPF_JIT:
|
|
Maps
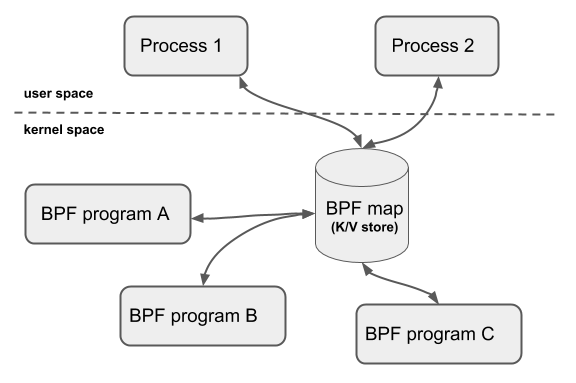
BPF Map是驻留在内核空间中的高效key/value store,包含多种类型的Map,由内核实现其功能。
BPF Map的交互场景有一下几种:
- BPF 程序和用户态程序的交互:BPF 程序运行完,得到的结果存储到 map 中,供用户态程序通过文件描述符访问
- BPF 程序和内核态程序的交互:和 BPF 程序以外的内核程序交互,也可以使用 map 作为中介
- BPF 程序间交互:如果 BPF 程序内部需要用全局变量来交互,但是由于安全原因 BPF 程序不允许访问全局变量,可以使用 map 来充当全局变量
- BPF Tail call:Tail call 是一个 BPF 程序跳转到另一 BPF 程序,BPF 程序首先通过 BPF_MAP_TYPE_PROG_ARRAY 类型的 map 来知道另一个 BPF 程序的指针,然后调用 tail_call() 的 helper function 来执行 Tail call
共享 map 的 BPF 程序不要求是相同的程序类型,例如 tracing 程序可以和网络程序共享 map,单个 BPF 程序目前最多可直接访问 64 个不同 map。
当前可用的 通用 map 有:
|
|
以上 map 都使用相同的一组 BPF 辅助函数来执行查找、更新或删除操作,但各自实现了不同的后端,这些后端各有不同的语义和性能特点。随着多 CPU 架构的成熟发展,BPF Map 也引入了 per-cpu 类型,如BPF_MAP_TYPE_PERCPU_HASH、BPF_MAP_TYPE_PERCPU_ARRAY等,当你使用这种类型的 BPF Map 时,每个 CPU 都会存储并看到它自己的 Map 数据,从属于不同 CPU 之间的数据是互相隔离的,这样做的好处是,在进行查找和聚合操作时更加高效,性能更好,尤其是你的 BPF 程序主要是在做收集时间序列型数据,如流量数据或指标等。
当前内核中的 非通用 map 有:
|
|