K8s通信问题
- 容器间通信:即同一个Pod内多个容器间通信,通常使用loopback来实现。
- Pod间通信:K8s要求,Pod和Pod之间通信必须使用Pod-IP 直接访问另一个Pod-IP
- Pod与Service通信:即PodIP去访问ClusterIP,当然,clusterIP实际上是IPVS或iptables规则的虚拟IP,是没有TCP/IP协议栈支持的。但不影响Pod访问它.
- Service与集群外部Client的通信,即K8s中Pod提供的服务必须能被互联网上的用户所访问到。
需要注意的是,k8s集群初始化时的service网段,pod网段,网络插件的网段,以及真实服务器的网段,都不能相同,如果相同就会出各种各样奇怪的问题,而且这些问题在集群做好之后是不方便改的,改会导致更多的问题,所以,就在搭建前将其规划好。
理解CNI
cni作为容器网络的统一标准,让各个容器管理平台(k8s,mesos等)都可以通过相同的接口调用各式各样的网络插件(flannel,calico,weave等)来为容器配置网络。容器管理系统与网络插件之间的关系图如下所示。
我们可以发现其实cni定义的就是一组容器运行时(containerd,rkt等)与网络插件之间的规范定义。其目标是为容器创建基于插件的通用网络解决方案。cni在规范(https://github.com/containernetworking/cni/blob/master/SPEC.md)中定义了:
- cni规范为容器定义一个linux网络命名空间。因为像docker这样的容器运行时会为每个docker容器都创建一个新的网络命名空间。
- cni的网络定义存储为json格式。
- 网络定义通过STDIN输入流传输到插件,这意味着宿主机上不会存储网络配置文件。
- 其他的配置参数通过环境变量传递给插件
- cni插件为可执行文件。
- cni插件负责联通容器网络,也就是说,它要完成所有的功能才能使容器连入网络。在docker中,这些工作包括以某种方式将容器网络命名空间连接回宿主机。
- cni插件负责调用ipam插件,ipam负责ip地址分配和设置容器所需的路由。# 一、简述你知道的几种CNI网络插件,并详述其工作原理。K8s常用的CNI网络插件 (calico && flannel),简述一下它们的工作原理和区别.
1、calico根据 iptables规则 进行路由转发,并没有进行封包,解包的过程,这和flannel比起来效率就会快多
calico包括如下重要组件:Felix,etcd,BGP Client,BGP Route Reflector。下面分别说明一下这些组件。
Felix:主要负责路由配置以及ACLS规则的配置以及下发,它存在在每个node节点上。
etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
BGPClient(BIRD), 主要负责把 Felix写入 kernel的路由信息分发到当前 Calico网络,确保 workload间的通信的有效性;
BGPRoute Reflector(BIRD), 大规模部署时使用,摒弃所有节点互联的mesh模式,通过一个或者多个 BGPRoute Reflector 来完成集中式的路由分发
通过将整个互联网的可扩展 IP网络原则压缩到数据中心级别,Calico在每一个计算节点利用 Linuxkernel 实现了一个高效的 vRouter来负责数据转发,而每个vRouter通过 BGP协议负责把自己上运行的 workload的路由信息向整个Calico网络内传播,小规模部署可以直接互联,大规模下可通过指定的BGProute reflector 来完成。这样保证最终所有的workload之间的数据流量都是通过 IP包的方式完成互联的。
2、Flannel的工作原理:
Flannel实质上是一种“覆盖网络(overlay network)”,也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,目前已经支持UDP、VxLAN、AWS VPC和GCE路由等数据转发方式。
默认的节点间数据通信方式是UDP转发。
工作原理:
数据从源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel0虚拟网卡( 先可以不经过docker0网卡,使用cni模式 ),这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外一端。
Flannel通过Etcd服务维护了一张节点间的路由表,详细记录了各节点子网网段 。
源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直接进入目的节点的flannel0虚拟网卡,然后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一下的有docker0路由到达目标容器。
flannel在进行路由转发的基础上进行了封包解包的操作,这样浪费了CPU的计算资源。
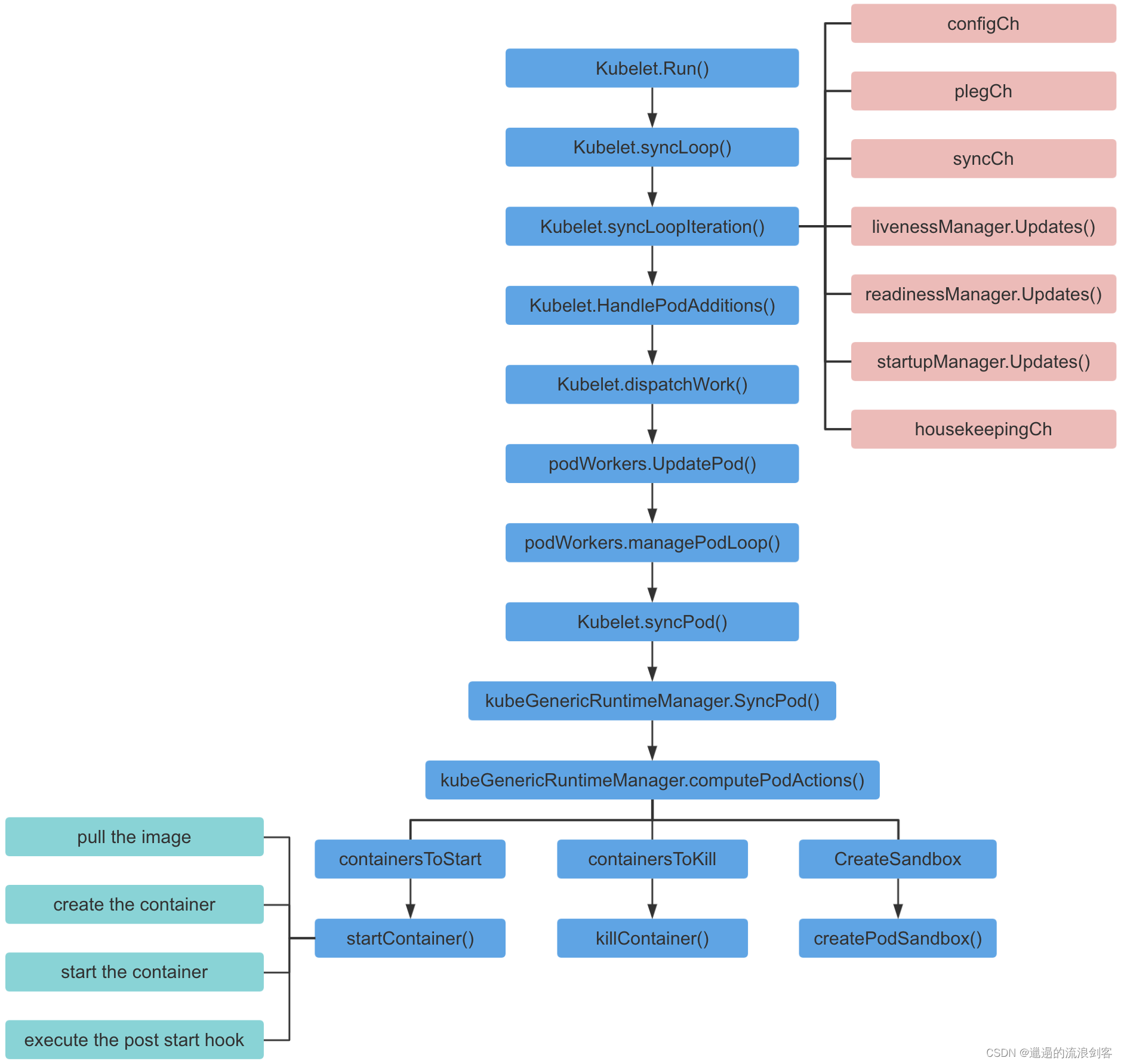
二、从POD创建到调用到CNI插件的流程图
从整个k8s集群来看
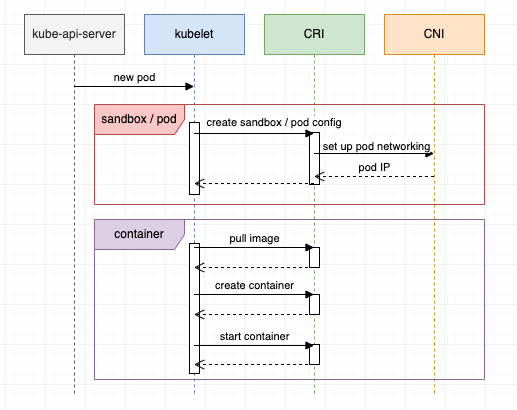
kubelet一些关键函数说明
参考文章:https://developer.aliyun.com/learning/course/572/detail/7866
三、如何开发自己的CNI插件
CNI插件的实现通常包含两个部分:
- 一个二进制的CNI插件去配置Pod网卡和IP地址。这一步配置完成后相当于给Pod插上了一条网线:有了自己的IP、自己的网卡;
- 一个Daemon进程去管理Pod之间的网络打通。这一步相当于将Pod真正连上网络,让Pod之间能够互通。
给Pod插上网线
- 给Pod准备虚拟网卡
- 创建“veth”虚拟网卡对
- 将一端的网卡挪到Pod中
- 给Pod分配IP地址
- 给Pod分配集群中唯一的IP地址
- 一般把Pod网段按Node分段
- 每个Pod再从Node段中分配IP
- 配置Pod的IP和路由
- 给Pod的虚拟网卡网址分配到的IP
- 给Pod的网卡上配置集群网段的路由
- 在宿主机上配置到Pod的IP地址的路由到对端虚拟网卡上
给Pod连上网络
刚才是给Pod插上网线,也就是说分配了IP地址和路由表。接下来说明怎么让每一个Pod的IP地址在集群里都能被访问到。
一般是在CNI的daemon进程中去做这些网络打通的事情。
- 首先CNI在每个节点上运行的daemon进程会学习到集群所有Pod的IP地址及其所在节点的信息。学习的方式通过监听K8s APIserver,拿到现有Pod的IP地址以及节点,并且新的节点和新的Pod在创建的时候也能通知到每个daemon;
- 拿到Pod以及Node相关信息后,再去配置网络进行打通。
- 首先daemon回创建到整个集群所有节点的通道。这里的通道是个抽象的概念, 具体实现一般是通过overlay隧道等。
- 第二部是将所有Pod的IP地址跟上一步创建的通道关联起来。关联也是个抽象的概念,具体实现通常是通过linux路由、fdb转发表或者ovs流表完成的。