Bridge模式
当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。从docker0子网中分配一个 IP 给容器使用,并设置 docker0 的 IP 地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备,Docker 将 veth pair 设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到 docker0 网桥中。可以通过brctl show命令查看。
bridge模式是 docker 的默认网络模式,不写–net参数,就是bridge模式。使用docker run -p时,docker 实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL查看。bridge模式如下图所示:
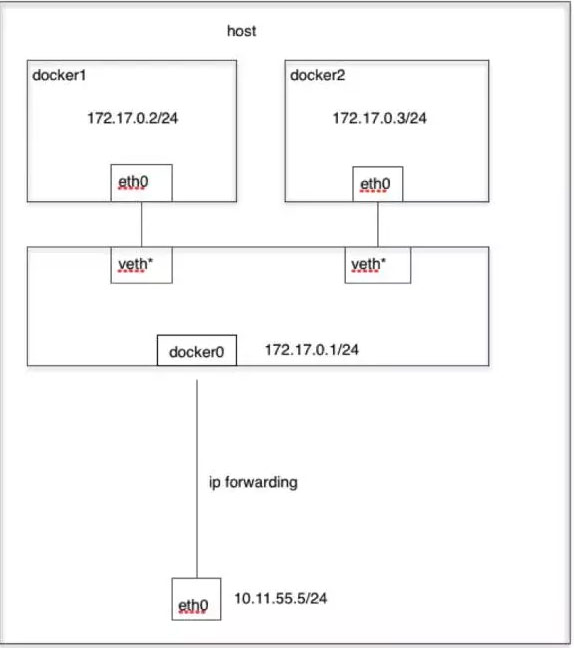
演示: 演示:
$ docker run -tid --net=bridge --name docker_bri1 \\
ubuntu-base:v3
docker run -tid --net=bridge --name docker_bri2 \\
ubuntu-base:v3
$ brctl show
$ docker exec -ti docker_bri1 /bin/bash
$ ifconfig –a
$ route –n
如果你之前有 Docker 使用经验,你可能已经习惯了使用--link参数来使容器互联。
随着 Docker 网络的完善,强烈建议大家将容器加入自定义的 Docker 网络来连接多个容器,而不是使用 –link 参数。
1.占位符分别代表了什么?
golang 的fmt 包实现了格式化I/O函数,类似于C的 printf 和 scanf。 定义示例类型和变量
type Human struct {
Name string
}
var people = Human{Name:"zhangsan"}
2 普通占位符
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| %v | 相应值的默认格式。 | Printf("%v", people) | {zhangsan} |
| %+v | 打印结构体时,会添加字段名 | Printf("%+v", people) | {Name:zhangsan} |
| %#v | 相应值的Go语法表示 | Printf("#v", people) | main.Human{Name:“zhangsan”} |
| %T | 相应值的类型的Go语法表示 | Printf("%T", people) | main.Human |
| %% | 字面上的百分号,并非值的占位符 | Printf("%%") | % |
3 布尔占位符
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| %t | true或false | Printf("%t", true) | true |
4 整数占位符
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| %b | 二进制表示 | Printf("%b", 5) | 101 |
| %c | 相应Unicode码点锁表示的字符 | Printf("%c", 0x4e2d) | 中 |
| %d | 十进制表示 | Printf("%d", 0x12) | 18 |
| %o | 八进制表示 | Printf("%d", 10) | 12 |
| %q单引号围绕的字符字面值,由Go语法安全地转义 | Printf("%q", 0x4E2D) | ‘中’ | |
| %x | 十六进制表示,字母形式为小写 a-f | Printf("%x", 13) | d |
| %X | 十六进制表示,字母形式为大写 A-F | Printf("%x", 13) | D |
| %U | Unicode格式:U+1234,等同于 “U+%04X” | Printf("%U", 0x4E2D) | U+4E2D |
5 浮点数和复数的组成部分(实部和虚部)
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| %b | 无小数部分的,指数为二的幂的科学计数法, 与 strconv.FormatFloat 的 ‘b’ 转换格式一致。例如 -123456p-78 | ||
| %e | 科学计数法,例如 -1234.456e+78 | Printf("%e", 10.2) | 1.020000e+01 |
| %E | 科学计数法,例如 -1234.456E+78 | Printf("%e", 10.2) | 1.020000E+01 |
| %f | 有小数点而无指数,例如 123.456 | Printf("%e", 10.2) | 10.200000 |
| %g | 根据情况选择 %e 或 %f 以产生更紧凑的(无末尾的0)输出 | Printf("%g", 10.20) | 10.2 |
| %G | 根据情况选择 %E 或 %f 以产生更紧凑的(无末尾的0)输出 | Printf("%G", 10.20+2i) | (10.2+2i) |
6 字符串与字节切片
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| %s | 输出字符串表示(string类型或[]byte) | Printf("%s", []byte(“Go语言”)) | Go语言 |
| %q | 双引号围绕的字符串,由Go语法安全地转义 | Printf("%q", “Go语言”) | “Go语言” |
| %x | 十六进制,小写字母,每字节两个字符 | Printf("%x", “golang”) | 676f6c616e67 |
| %X | 十六进制,大写字母,每字节两个字符 | Printf("%X", “golang”) | 676F6C616E67 |
7 指针
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| %p | 十六进制表示,前缀 0x | Printf("%p", &people) | 0x4f57f0 |
8 其它标记
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| + | 总打印数值的正负号;对于%q(%+q)保证只输出ASCII编码的字符。 | Printf("%+q", “中文”) | “\u4e2d\u6587” |
| - | 在右侧而非左侧填充空格(左对齐该区域) | ||
| # | 备用格式:为八进制添加前导 0(%#o) 为十六进制添加前导 0x(%#x)或 0X(%#X),为 %p(%#p)去掉前导 0x; 如果可能的话,%q(%#q)会打印原始(即反引号围绕的)字符串; 如果是可打印字符,%U(%#U)会写出该字符的 Unicode 编码形式(如字符 x 会被打印成 U+0078 ‘x’)。 | Printf("%#U", ‘中’) | U+4E2D |
| ’ ' | (空格)为数值中省略的正负号留出空白(% d); 以十六进制(% x, % X)打印字符串或切片时,在字节之间用空格隔开 | ||
| 0 | 填充前导的0而非空格;对于数字,这会将填充移到正负号之后 |
互斥锁
用一个互斥锁来在Go协程间安全的访问数据
package main
import (
"fmt"
"math/rand"
"runtime"
"sync"
"sync/atomic"
"time"
)
func main() {
var state = make(map[int]int)
var mutex = &sync.Mutex{}
var ops int64 = 0
for r := 0; r < 100; r++ {
// 运行100个go协程来重复读取state
go func() {
total := 0
for {
key := rand.Intn(5)
mutex.Lock()
total += state[key]
mutex.Unlock()
atomic.AddInt64(&ops, 1)
runtime.Gosched() // 为了确保这个Go协程不会在调度中饿死,我们在每次操作后明确的使用runtime.Gosched()进行释放。是自动处理的。
}
}()
}
for w := 0; w < 10; w++ { // 模拟写入操作
go func() {
for {
key := rand.Intn(5)
val := rand.Intn(100)
mutex.Lock()
state[key] = val
mutex.Unlock()
atomic.AddInt64(&ops, 1)
runtime.Gosched()
}
}()
}
time.Sleep(time.Second)
opsFinal := atomic.LoadInt64(&ops)
fmt.Println("ops:", opsFinal)
mutex.Lock() //对 state 使用一个最终的锁,显示它是如何结束的。
fmt.Println("state:", state)
mutex.Unlock()
}
尽量减少锁的持有时间
- 细化锁的粒度。通过细化锁的粒度来减少锁的持有时间以及避免在持有锁操作的时候做各种耗时的操作。
- 不要在持有锁的时候做 IO 操作。尽量只通过持有锁来保护 IO 操作需要的资源而不是 IO 操作本身:
func doSomething() {
m.Lock()
item := ...
http.Get() // 各种耗时的 IO 操作
m.Unlock()
}
// 改为
func doSomething() {
m.Lock()
item := ...
m.Unlock()
http.Get()
}
善用 defer 来确保在函数内正确释放
通过 defer 可以确保不会遗漏释放锁操作,避免出现死锁问题,以及避免函数内非预期的 panic 导致死锁的问题 不过使用 defer 的时候也要注意别因为习惯性的 defer m.Unlock() 导致无意中在持有锁的时候做了 IO 操作,出现了非预期的持有锁时间太长的问题。
// 非预期的在持有锁期间做 IO 操作
func doSomething() {
m.Lock()
defer m.Unlock()
item := ...
http.Get() // 各种耗时的 IO 操作
}
在适当时候使用 RWMutex
当确定操作不会修改保护的资源时,可以使用 RWMutex 来减少锁等待时间(不同的 goroutine 可以同时持有 RLock, 但是 Lock 限制了只能有一个 goroutine 持有 Lock):
使用场景:
我需要完成一项任务,但是这项任务需要满足一定条件才可以执行,否则我就等着。
那我可以怎么获取这个条件呢?一种是循环去获取,一种是条件满足的时候通知我就可以了。显然第二种效率高很多。
通知的方式的话,golang里面通知可以用channel的方式
var mail = make(chan string)
go func() {
<- mail
fmt.Println("get chance to do something")
}()
time.Sleep(5*time.Second)
mail <- "moximoxi"
但是channel的方式还是比较适合一对一,一对多并不是很适合。下面就来介绍一下另一种方式:sync.Cond
sync.Cond就是用于实现条件变量的,是基于sync.Mutex的基础上,增加了一个通知队列,通知的线程会从通知队列中唤醒一个或多个被通知的线程。
主要有以下几个方法:
sync.NewCond(&mutex):生成一个cond,需要传入一个mutex,因为阻塞等待通知的操作以及通知解除阻塞的操作就是基于sync.Mutex来实现的。
sync.Wait():用于等待通知
sync.Signal():用于发送单个通知
sync.Broadcat():用于广播
先找到一个sync.Cond的基本用法
package main
import (
"fmt"
"sync"
"time"
)
var locker sync.Mutex
var cond = sync.NewCond(&locker)
// NewCond(l Locker)里面定义的是一个接口,拥有lock和unlock方法。
// 看到sync.Mutex的方法,func (m *Mutex) Lock(),可以看到是指针有这两个方法,所以应该传递的是指针
func main() {
for i := 0; i < 10; i++ {
go func(x int) {
cond.L.Lock() // 获取锁
defer cond.L.Unlock() // 释放锁
cond.Wait() // 等待通知,阻塞当前 goroutine
// 通知到来的时候, cond.Wait()就会结束阻塞, do something. 这里仅打印
fmt.Println(x)
}(i)
}
time.Sleep(time.Second * 1) // 睡眠 1 秒,等待所有 goroutine 进入 Wait 阻塞状态
fmt.Println("Signal...")
cond.Signal() // 1 秒后下发一个通知给已经获取锁的 goroutine
time.Sleep(time.Second * 1)
fmt.Println("Signal...")
cond.Signal() // 1 秒后下发下一个通知给已经获取锁的 goroutine
time.Sleep(time.Second * 1)
cond.Broadcast() // 1 秒后下发广播给所有等待的goroutine
fmt.Println("Broadcast...")
time.Sleep(time.Second * 5) // 睡眠 1 秒,等待所有 goroutine 执行完毕
}
上述代码实现了主线程对多个goroutine的通知的功能。
抛出一个问题:
主线程执行的时候,如果并不想触发所有的协程,想让不同的协程可以有自己的触发条件,应该怎么使用?
下面就是一个具体的需求:
有四个worker和一个master,worker等待master去分配指令,master一直在计数,计数到5的时候通知第一个worker,计数到10的时候通知第二个和第三个worker。
首先列出几种解决方式
1、所有worker循环去查看master的计数值,计数值满足自己条件的时候,触发操作 »»»»>弊端:无谓的消耗资源
2、用channel来实现,几个worker几个channel,eg:worker1的协程里<-channel(worker1)进行阻塞,计数值到5的时候,给worker1的channel放入值,
阻塞解除,worker1开始工作。 »»»>弊端:channel还是比较适用于一对一的场景,一对多的时候,需要起很多的channel,不是很美观
3、用条件变量sync.Cond,针对多个worker的话,用broadcast,就会通知到所有的worker。
厨师长分享48款火锅蘸碟,不管来自哪里,总有一款适合您 - 哔哩哔哩 (bilibili.com)
一、味碟
1、蒜泥油碟
蒜末、香菜末、葱末、香油、盐
2、北方涮肉碟
熟花生沫、芝麻酱、韭菜花酱、腐乳、葱末
3、麻酱味碟
芝麻酱、腐乳、韭菜花酱、蚝油、白糖、熟花生末、蒜末、香菜末、葱末、香油
4、蒜香味碟
金蒜(油炸蒜)、蚝油、葱末、生抽、紫菜、香油
5、海鲜味碟
虾皮、紫菜(切碎的紫菜)、香菜沫、香油、生抽、鸡精、香醋
6、微麻清汤碟
青花椒粉、盐、鸡精、葱末、香醋、生抽、香油
7、经典油醋碟
生抽、花生油、苹果醋、蜂蜜、葱末
8、香醋酱汁碟
洋葱末、香醋、生抽、柠檬汁、蜂蜜、香油、黑胡椒粉
9、鱼香味碟
蚝油、香醋、生抽、白糖、盐、葱末
10、姜汁味碟
姜末、蒜末、盐、花生油
11、沙姜味碟
沙姜粉、生抽、花生油、葱末
12、葱油味碟
葱油、蒜末、生抽
13、盐焗味碟
姜末、蒜末、生抽、葱末、盐焗鸡粉、花生油
14、沙拉酱碟
沙拉酱、薄荷叶末、酸奶、蜂蜜、橙汁(浓缩)
15、千岛酱碟
酸黄瓜酱、洋葱末、番茄沙司、酸奶、橄榄油
16、椰奶花生酱碟
红糖末、椰奶、花生酱、柠檬汁、海鲜酱、熟花生末、蚝油
17、香醋酱碟
洋葱末、黑胡椒粉、蜂蜜、香油、生抽、香醋、柠檬汁
二、红油蘸碟
1、经典油碟
蒜末、小米辣、蚝油、香油、葱末、香菜末
2、经典升级版油碟
蒜末、小米辣、蚝油、香油、葱末、香菜末、熟花生末、熟芝麻
3、经典豪华版油碟
蒜末、小米辣、蚝油、香油、葱末、香菜末、熟花生末、熟芝麻、折耳根末、大头菜末、熟豌豆
4、经典改良版
蒜末、小米辣、香油、香醋、生抽、香菜末、葱末。
5、红油味碟
蒜末、小米辣、生抽、红油、葱末、香菜末
6、豆瓣酱味碟
炒香的豆瓣酱、葱末、香菜末
7、香辣酱碟
香辣酱、蒜末、小米辣、香油、红油、葱末、香菜末
8、清汤锅碟
小米辣、蒜末、香醋、生抽、葱末、香菜末
9、韭香味碟
韭菜花酱、蒜末、小米辣、韭菜末、蚝油、生抽、葱末
10、韩式辣酱碟
韩式辣酱、熟芝麻、蒜末、生抽、白糖、香醋、洋葱末、香油
11、泰式酸辣碟
洋葱末、小米辣、蒜末、香茅草末、黄柠檬片、鱼露、柠檬汁、香菜末
12、柠香味碟
蒜末、小米辣、熟花生末、白糖、柠檬汁、香菜末、葱末
13、百香果味碟
蜂蜜、百香果、洋葱末、小米辣、生抽、香油、柠檬汁、香菜末
14、酸辣麻酱碟
熟芝麻、洋葱末、小米辣、生抽、蚝油、香醋、芝麻酱、香菜末
15、烧烤味碟
蒜末、小米辣,熟芝麻、孜然粉、生抽、蚝油、白糖、辣椒面
一、消息队列的演进
分布式消息队列中间件是大型分布式系统中常见的中间件。消息队列主要用来解决应用耦合、异步消息、流量削峰等问题,具有高性能、高可用、可伸缩和最终一致性等特点。消息队列已经逐渐成为企业应用系统内部通信的核心手段,使用较多的消息队列有RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、Pulsar等,此外,利用数据库(如Redis、MySQL等)也可实现消息队列的部分基本功能。
1.基于OS的MQ
单机消息队列可以通过操作系统原生的进程间通信机制来实现,如消息队列、共享内存等。比如我们可以在共享内存中维护一个双端队列,消息产出进程不停地往队列里添加消息,同时消息消费进程不断地从队尾取出这些消息。添加消息的任务称为producer,取出消息的称为consumer。 单机MQ易于实现,但是缺点明显:依赖于单机OS的IPC(进程间通信)机制。无法实现分布式的消息传递,并且消息队列的容量也受限于单机资源。
2.基于DB的MQ
使用存储组件(如mysql、redis等)存储消息,然后在消息的生产侧和消费侧实现消息的生产消费逻辑,从而实现MQ功能。以redis为例,可以使用Redis自带的list实现。Redis list使用lpush命令,从队列左边插入数据;使用rpop命令,从队列右边取出数据。 与单机MQ相比,该方案至少满足了分布式,但是仍然带有很多无法接受的缺陷。
- 热key性能问题:不论使用codis还是twemproxy这种集群方案,对某个队列的读写请求最终都会落到同一台redis实例上,并且无法通过扩容来解决问题。如果对于某个list的并发读写非常高,就产生了无法解决的热key,严重可能导致系统崩溃。
- 没有消费确认机制:每当执行rpop消费一条数据,那条消息就被从list中永久删除了。如果消费者消费失败,这条消息也没法找回了。
- 不支持多订阅者:一条消息只能被一个消费者消费。rpop之后就没了。如果队列中存储的是应用的日志,对于同一条消息,监控系统需要消费它来进行可能的报警,BI系统需要消费它来绘制报表,链路追踪需要消费它来绘制调用关系。。。这种场景redis酒办不到了。
- 不支持二次消费:一条消息 rpop 之后就没了。如果消费者程序运行到一半发现代码有 bug,修复之后想从头再消费一次就不行了。
3.专用分布式MQ中间件
随着发展,一个真正的消息队列,已经不仅仅是一个队列那么简单了,业务对MQ的吞吐量、扩展性、稳定性、可靠性等都提出了严苛的要求。因此,专用的分布式消息中间件开始大量出现。常见的有 RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、Pulsar 等等。
二、消息队列的设计要点
消息队列本质上是一个消息的转发系统,把一次RPC就可以直接完成的消息投递,转换成多次RPC间接完成,这其中包含两个关键环节:
- 消息转储
- 消息投递:时机和对象
基于此,消息队列的整体设计思路是:
- 确定整体的数据流向:如producer发送给MQ,MQ转发给consumer,consumer回复消费确认,消息删除、消息备份等。
- 利用RPC将数据流串起来,最好基于现有的RPC框架,尽量做到无状态、方便水平扩展。
- 存储选型,综合考虑性能、可靠性和开发维护成本等诸多因素。
- 消息投递,消费模式push、pull。
- 消费关系维护,单播,多播等,可以利用zk、config server等保存消费关系。
- 高级特性,如可靠投递、重复消息,顺序消息等,很多高级特性之间是互相制约的关系,这里要充分结合应用场景做出取舍。

1.MQ基本特性
RPC通信
MQ组件要实现和生产者以及消费者进行通行功能,这里涉及到RPC通信问题。消息队列的RPC,和普通的RPC没有本质区别。对于负载均衡、服务发现、序列化协议等等问题都可以借助现有RPC框架来实现,避免重复造轮子。
存储系统
有两种:持久化和非持久化 对于要求投递性能的:非持久化存储。消息不落地直接暂存内存,尝试几次failover,最终投递出去也未尝不可。 对于要求消息的可靠性的(断电不丢失):持久化存储。
高可用
MQ的高可用,依赖于RPC和存储的高可用。冗长RPC服务自身都具有服务自动发现,负载均衡等功能,保证了其高可用。 存储的高可用,例如kafka,使用分区加主备模式,保证每一个分区的高可用性,也就是每一个分区至少要有一个备份且需要做数据的同步。
推拉模型
push和pull模型各有利弊
- 慢消费 慢消费是push模型最大的致命伤,如果消费者的速度比发送者的速度慢的多,会出现两种恶劣的情况: 1. 消息在broker的堆积。假设这些消息都是有用切无法丢弃的,则这些消息就要一直在broker中保存。 2. broker推送给consumer的消息consumer无法处理,此时consumer只能拒绝或者返回错误。 而pull模式下,consumer可以按需消费,主动去拉消息。而broker堆积消息也会相对简单,无需记录每一个要发送消息的状态,只需维护所有消息的队列和偏移量就可以,所以对于慢消费,消息量有限且到来的速度不均匀的情况,pull模式比较合适。
- 消息延迟与忙等 这是pull模式最大的短板。由于主动权在消费方,消费方无法准确地决定何时去拉取最新的消息。如果没有pull到消息,则需要等待一段时间重新pull。
消息投放时机
即消费者应该在什么时机消费消息。有三种方式:
- 攒够了一定数量就投放
- 到达了一定时间就投放
- 有新的数据到来就投放 要根据具体的业务场景来决定选择哪种方式。比如,对及时性要求高的数据,可采用方式3.
消息投放对象
不管是JMS规范中的Topic/Queue,kafka里面的Topic/Partition/ConsumerGroup,还是AMQP(如RabbitMQ)的exchange等等,都是为了维护消息的消费关系而抽象出来的概念。本质上,消息的消费无外乎点到点的一对一单播、或一对多广播。另外比较特殊的场景是组间广播、组内单播。比较通用的设计是,不同的组注册不同的订阅,支持组间广播。组内不同的机器,如果注册一个相同的ID,则单播;如果注册不同的ID(如IP地址+端口号),则广播。 例如pulsar支持订阅模型有:
- Exclusive:独占性,一个订阅只能有一个消费者消费消息。
- Failover:灾备型,一个订阅同时只有一个消费者,可以用多个备消费者。一旦主消费者故障则备消费者接管。不会出现同时有两个活跃的消费者。
- Shared:共享型,一个订阅中同时可以有多个消费者,多个消费者共享topic中的消息。
- Key_Shared:键共享型,多个消费者各取一部分消息。 通常会在公共存储上维护广播关系,如config server、zookeeper等。
2.队列的高级特性
常见的高级特性有可靠投递、消息丢失、消失重复、事务等等,他们并非是MQ必备的特性。由于这些特性可能是相互制约的,所以不可能完全兼顾。所以要依照业务的需求,来仔细衡量各种特性实现的成本、利弊,最终做出最为合理的设计。
Go 程序从 main 包的 main() 函数开始,在程序启动时,Go 程序就会为 main() 函数创建一个默认的 goroutine。
所有 goroutine 在 main() 函数结束时会一同结束。
若在启用的goroutine中不使用WaitGroup的话会因为main函数已执行完,阻塞的函数与发送信号的函数会一同结束,不能真正实现阻塞的功能。
因此可以使用WaitGroup来实现阻塞的功能。
如下为不加WaitGroup时的版本
package main
import (
"fmt"
"time"
)
var closeCh = make(chan struct{})
func main() {
// var wg sync.WaitGroup
fmt.Println("start main func")
// wg.Add(1)
go func() {
fmt.Println("waiting for signal")
<-closeCh
fmt.Println("got signal.")
// wg.Done()
}()
// wg.Add(1)
go func() {
fmt.Println("preparing for signal:")
for i := 0; i < 3; i++ {
fmt.Println(">>>>")
time.Sleep(time.Second * 1)
}
closeCh <- struct{}{}
fmt.Println("sent signal.")
// wg.Done()
}()
// wg.Wait()
}
执行结果
1. 首先声明两个基础结构体(其他语言的基类吧:))
type Animal struct {
Name string
}
type Old struct {
Age int
}
并给Animal类增加一个方法Walk()
func (a *Animal) Walk() {
fmt.Println("Animal Walk")
}
2. 让People类嵌套(继承)上面的Animal和Old类
这时可以有两种匿名嵌套(继承)方式
- 嵌套结构体指针
- 嵌套结构体
// 匿名嵌套,而且嵌套的是一个结构体指针
type People struct {
*Animal
Old
}
// 匿名嵌套,而且嵌套的是一个结构体
type People struct {
Animal
Old
}
非匿名嵌套的方式不太优雅
type People struct {
Animal Animal //非匿名嵌套Animal结构体
Old
}
3. new一个People
func NewPeople() *People {
return &People{
Animal: &Animal{Name: "bok"}, //嵌套结构体指针的方式,嵌套结构体时改成Animal: Animal{Name: "bok"} 即可
Old: Old{Age: 18},
}
}
4. 访问Walk()方法
people := NewPeople()
people.Animal.Walk() // 访问父类的Walk
people.Walk() // 访问自己的Walk方法(从父类Animal那里继承过来的)
// Animal Walk
// Animal Walk
5. 重写父类Walk()方法
func (p *People) Walk() {
fmt.Println("Poeple Walk")
}
people := NewPeople()
people.Animal.Walk() // 访问父类的Walk
people.Walk() // 访问自己的Walk方法(重写父类的Walk方法)
// Animal Walk
// Poeple Walk
6. 完整代码
package main
import "fmt"
type Animal struct {
Name string
}
type Old struct {
Age int
}
func (a *Animal) Walk() {
fmt.Println("Animal Walk")
}
type People struct {
*Animal
Old
}
func (p *People) Walk() {
fmt.Println("Poeple Walk")
}
func NewPeople() *People {
return &People{
Animal: &Animal{Name: "bok"},
Old: Old{Age: 18},
}
}
func main() {
people := NewPeople()
people.Animal.Walk()
people.Walk()
fmt.Println(people.Age)
fmt.Println(people.Name)
fmt.Printf("New people %v \n", people)
}
如何使用hugo
新建文章
hugo new posts/xxx.md
发布
hugo -d /target/dir