ip link命令格式
命令实例
ip link add link eth0 name eth0.10 type vlan id 10
| 命令实例 | 解释 |
|---|---|
| ip link add link eth0 name eth0.10 type vlan id 10 | 在设备eth0上创建新的vlan设备eth0.10 |
| ip link set eth0 up 或:ifconfig eth0 up | 开启eth0网卡 |
| ip link set eth0 down或:ifconfig eth0 down | 关闭eth0网卡 |
| ip link set eth0 promisc on | 开启网卡的混合模式 |
| ip link set eth0 promisc off | 关闭网卡的混合模式 |
| ip link set eth0 txqueuelen 1200 | 设置网卡队列长度 |
| ip link set eth0 mtu 1400 | 设置网卡最大传输单元 |
| ip link show | 显示网络接口信息 |
| ip link show eht0 | 显示eth0网卡的网络接口信息 |
| ip link show type vlan | 显示vlan类型设备 |
| ip link delete dev eth0.10 | 删除设备 |
[root@k8s-master ~]# ip link help link
Usage: ip link add [link DEV] [ name ] NAME
[ txqueuelen PACKETS ]
[ address LLADDR ]
[ broadcast LLADDR ]
[ mtu MTU ] [index IDX ]
[ numtxqueues QUEUE_COUNT ]
[ numrxqueues QUEUE_COUNT ]
type TYPE [ ARGS ]
ip link delete { DEVICE | dev DEVICE | group DEVGROUP } type TYPE [ ARGS ]
ip link set { DEVICE | dev DEVICE | group DEVGROUP }
[ { up | down } ]
[ type TYPE ARGS ]
[ arp { on | off } ]
[ dynamic { on | off } ]
[ multicast { on | off } ]
[ allmulticast { on | off } ]
[ promisc { on | off } ]
[ trailers { on | off } ]
[ carrier { on | off } ]
[ txqueuelen PACKETS ]
[ name NEWNAME ]
[ address LLADDR ]
[ broadcast LLADDR ]
[ mtu MTU ]
[ netns { PID | NAME } ]
[ link-netnsid ID ]
[ alias NAME ]
[ vf NUM [ mac LLADDR ]
[ vlan VLANID [ qos VLAN-QOS ] [ proto VLAN-PROTO ] ]
[ rate TXRATE ]
[ max_tx_rate TXRATE ]
[ min_tx_rate TXRATE ]
[ spoofchk { on | off} ]
[ query_rss { on | off} ]
[ state { auto | enable | disable} ] ]
[ trust { on | off} ] ]
[ node_guid { eui64 } ]
[ port_guid { eui64 } ]
[ xdp { off |
object FILE [ section NAME ] [ verbose ] |
pinned FILE } ]
[ master DEVICE ][ vrf NAME ]
[ nomaster ]
[ addrgenmode { eui64 | none | stable_secret | random } ]
[ protodown { on | off } ]
ip link show [ DEVICE | group GROUP ] [up] [master DEV] [vrf NAME] [type TYPE]
ip link xstats type TYPE [ ARGS ]
ip link afstats [ dev DEVICE ]
ip link help [ TYPE ]
TYPE := { vlan | veth | vcan | dummy | ifb | macvlan | macvtap |
bridge | bond | team | ipoib | ip6tnl | ipip | sit | vxlan |
gre | gretap | ip6gre | ip6gretap | vti | nlmon | team_slave |
bond_slave | ipvlan | geneve | bridge_slave | vrf | macsec }
k8siptable 了解
https://blog.csdn.net/qq_36183935/article/details/90734847
iptables工作流程
iptables是采用数据包过滤机制工作的,所以它会对请求的数据包的包头进行分析,并根据我们预先设定的规则进行匹配来决定是否可以进入主机。
① 防火墙是一层一层过滤的。实际是按照配置规则的顺序从上到下,从前到后进行过滤的; ② 如果匹配上规则,即明确表明阻止还是通过,此时数据包就不再向下匹配新规则了; ③ 如果所有规则中没有明确表明是阻止还是通过这个数据包,也就是没有匹配上规则,则按照默认策略进行处理; ④ 防火墙的默认规则是对应的链的所有的规则执行完成后才会执行的;
iptables四表五链
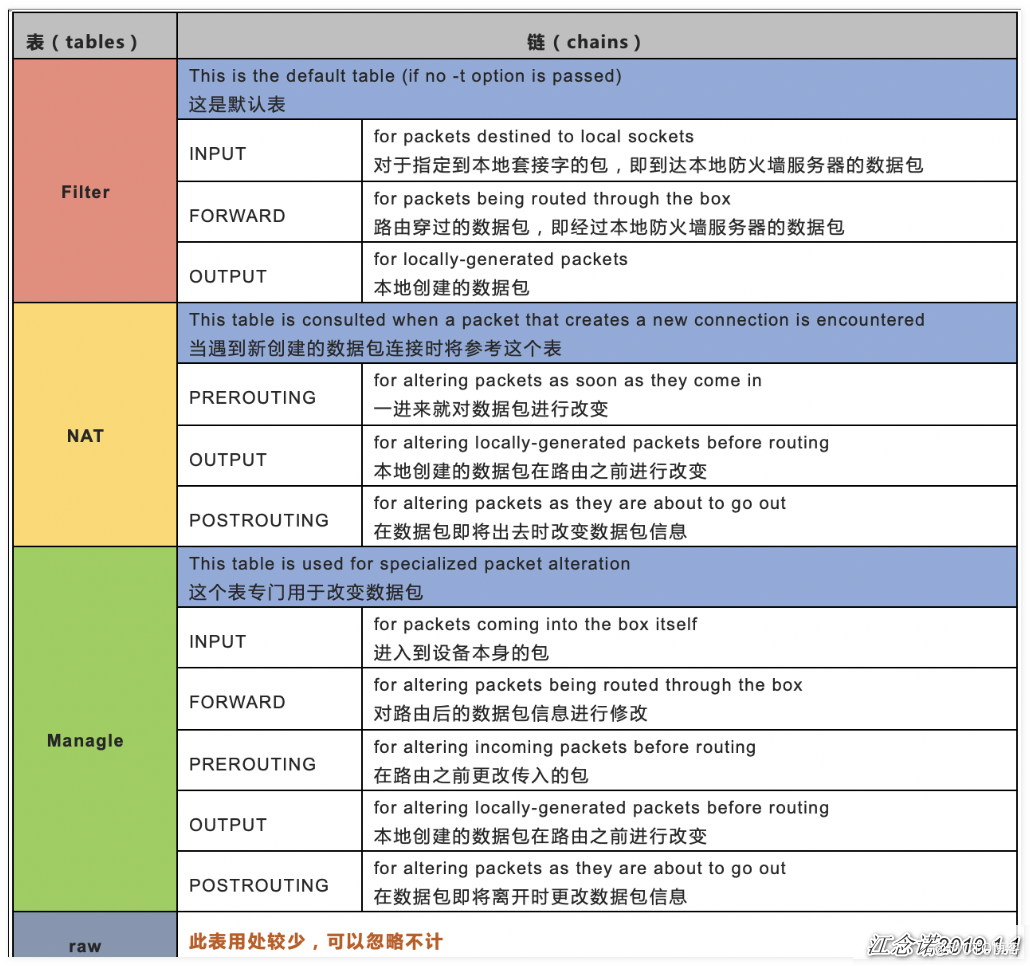
规则链包括(也称为5个钩子函数(hook functions)):
- INPUT链:处理输入数据包
- OUTPUT链:处理输出数据包
- FORWARD链:处理转发数据包
- PREROUTING链:用于目的地址转换(DNAT)
- POSTROUTING:用于源地址转换(SNAT)
但主要记住两张表即可:filter表和nat表.
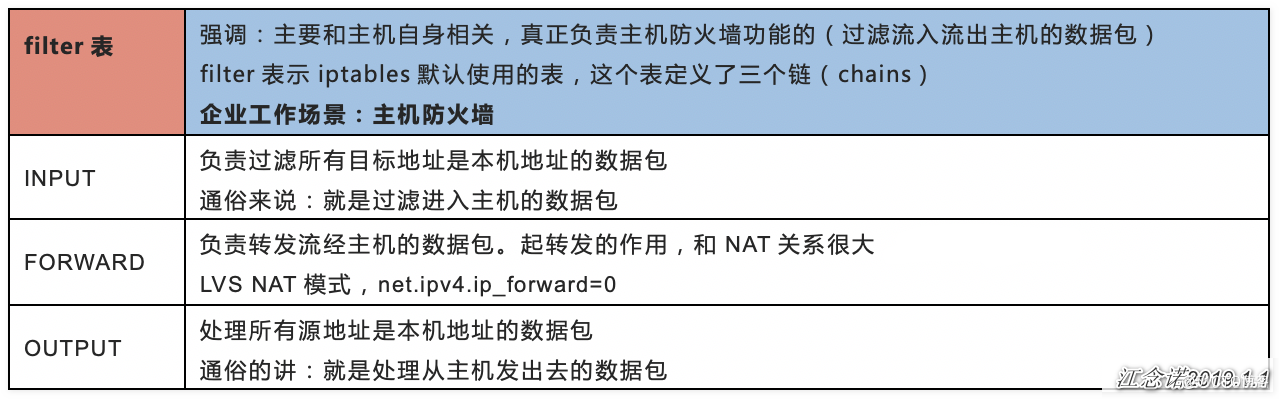
filter表
nat表

iptables工作原理
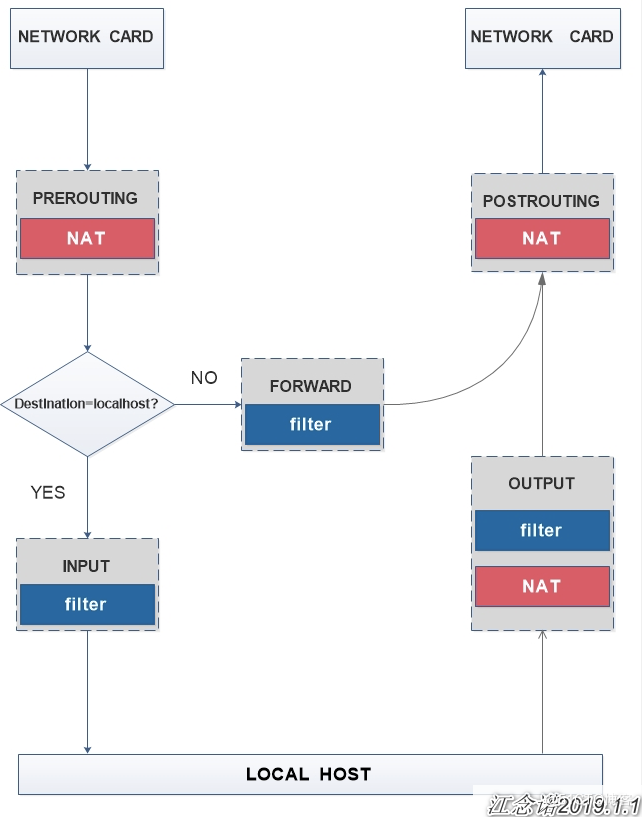
如图
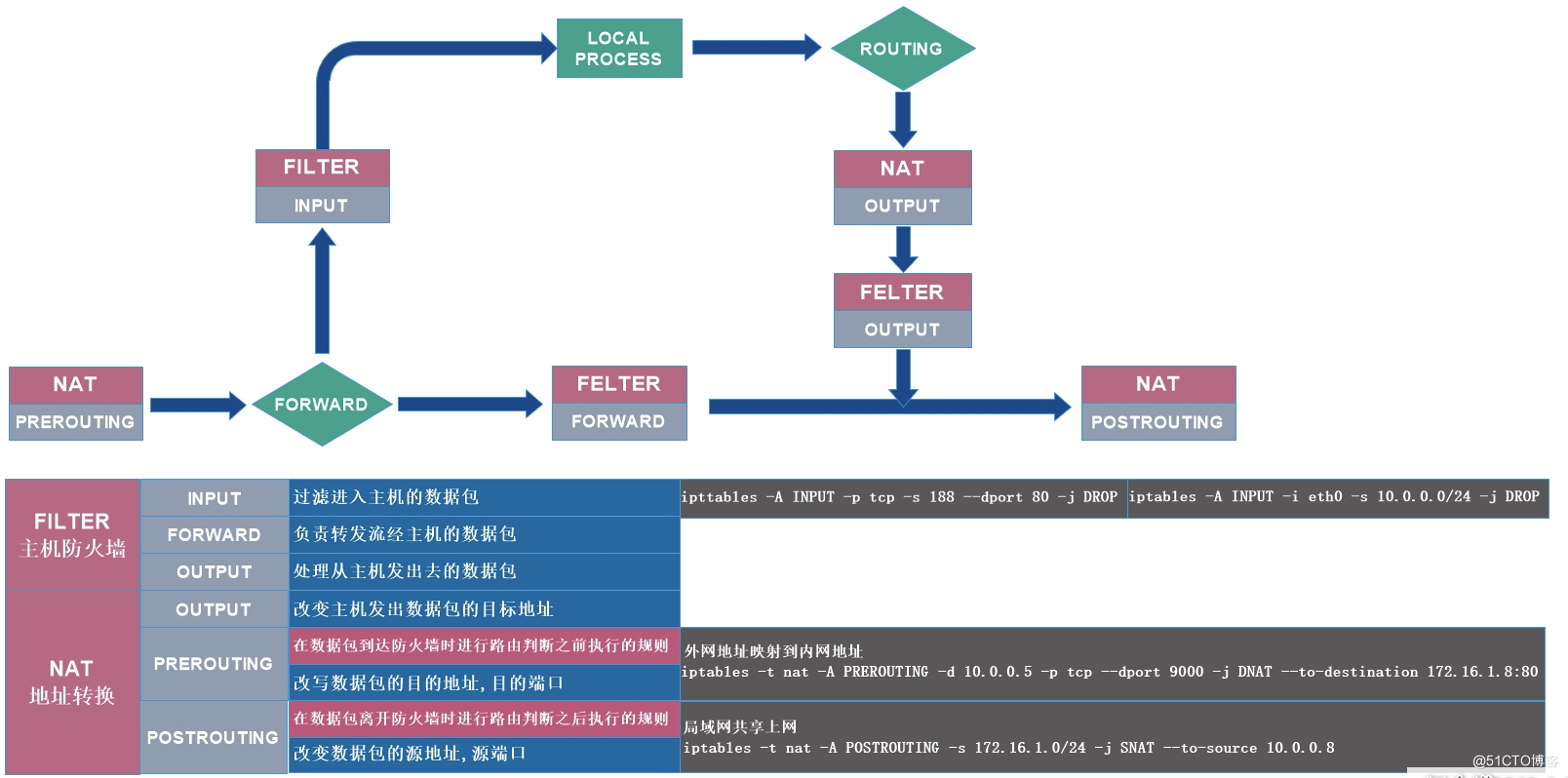
防火墙策略
防火墙策略一般分为两种,一种叫通策略,一种叫堵策略
- 通策略:默认门是关闭的,必须要定义谁能进
- 堵策略:大门是洞开的,但是必须有身份证,否则不能进.
所以我们要定义,让进来的进来,让出去的出去,所以通,是要全通,而堵,则是要选择.当我们定义策论的时候,要分别定义多条功能,其中:定义数据包中允许或者不允许的策略,filter过滤的功能,而定义地址转换的功能的则是nat选项. 为了让这些功能交替工作,我们指定出了"表"这个定义,来定义,区分各种不同的工作功能和处理方式.
用的比较多的功能有3个:
- filter定义允许或者不允许的,只能做在3个链上:INPUT,FORWARD,OUTPUT
- nat定义定制转换的,也只能做在3个链上:PREROUTING,OUTPUT,POSTROUTING
- mangle功能:修改报文数据,5个链都可以做:PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING
修改报文原数据就是来修改TTL的.能够实现将数据包的元数据拆开,在里面做标记/修改内容的.而防火墙标记,其实就是靠mangle表来实现的.
iptable/netfilter(这款软件)是工作在用户空间的,他可以让规则进行生效,本身不是一种服务,而且规则是立即生效的. 而iptable现在被做成了一个服务,可以进行启动,停止.. 启动,则规则直接生效,停止,则规则撤销.
iptables还支持自己定义链.但是自己定义的链,必须是跟某种特定的链关联起来的.在一个关卡设定,指定当有数据的时候专门去找某个特定的链来处理,当那个链处理完之后,再返回.接着在特定的链中继续检查.
注意:规则的次序非常关键,谁的规则越严格,应该放的越靠前,而检查规则的时候,是按照从上往下的方式进行检查的.
表名包括:
- raw :高级功能,如:网址过滤。
- mangle :数据包修改(QOS),用于实现服务质量。
- nat :地址转换,用于网关路由器。
- filter :包过滤,用于防火墙规则。
动作包括:
- ACCEPT :接收数据包。
- DROP :丢弃数据包。
- REDIRECT :重定向、映射、透明代理。
- SNAT :源地址转换。
- DNAT :目标地址转换。
- MASQUERADE :IP伪装(NAT),用于ADSL。
- LOG :日志记录。
iptables常用选项和参数
语法:
CustomResourceDefinition简介
在 Kubernetes 中一切都可视为资源,Kubernetes 1.7 之后增加了对 CRD 自定义资源二次开发能力来扩展 Kubernetes API,通过 CRD 我们可以向 Kubernetes API 中增加新资源类型,而不需要修改 Kubernetes 源码来创建自定义的 API server,该功能大大提高了 Kubernetes 的扩展能力。 当你创建一个新的CustomResourceDefinition (CRD)时,Kubernetes API服务器将为你指定的每个版本创建一个新的RESTful资源路径,我们可以根据该api路径来创建一些我们自己定义的类型资源。CRD可以是命名空间的,也可以是集群范围的,由CRD的作用域(scpoe)字段中所指定的,与现有的内置对象一样,删除名称空间将删除该名称空间中的所有自定义对象。customresourcedefinition本身没有名称空间,所有名称空间都可以使用。
https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions/
样例
# resourcedefinition.yaml
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# name must match the spec fields below, and be in the form: <plural>.<group>
name: crontabs.stable.example.com
spec:
# group name to use for REST API: /apis/<group>/<version>
group: stable.example.com
# list of versions supported by this CustomResourceDefinition
versions:
- name: v1
# Each version can be enabled/disabled by Served flag.
served: true
# One and only one version must be marked as the storage version.
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
image:
type: string
replicas:
type: integer
# either Namespaced or Cluster
scope: Namespaced
names:
# plural name to be used in the URL: /apis/<group>/<version>/<plural>
plural: crontabs
# singular name to be used as an alias on the CLI and for display
singular: crontab
# kind is normally the CamelCased singular type. Your resource manifests use this.
kind: CronTab
# shortNames allow shorter string to match your resource on the CLI
shortNames:
- ct
前面我们从pod的原理到生命周期介绍了pod的一些使用,作为kubernetes中最核心的对象,最基本的调度单元,我们可以发现pod中的属性还是非常繁多的,前面我们使用过一个volumes的属性,表示声明一个数据卷,我们可以通过命令kubectl explain pod.spec.volumes去查看该对象下面的属性非常多,前面我们只是简单的使用了hostpath和empryDir{}这两种模式,其中还有一种叫做downwardAPI这个模式和其他模式不一样的地方在于它不是为了存放容器的数据也不是用来进行容器和宿主机的数据交换的,而是让pod里的容器能够直接获取到这个pod对象本身的一些信息。
https://kubernetes.io/zh-cn/docs/concepts/workloads/pods/downward-api/
downwardAPI提供了两种方式用于将pod的信息注入到容器内部:
-
环境变量: 用于单个变量,可以将pod信息和容器信息直接注入容器内部
-
volume挂载:将pod信息生成为文件,直接挂载到容器内部中去
环境变量
[root@master1 ~]# cat env-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: env-pod
namespace: kube-system
spec:
containers:
- name: env-pod
image: busybox
command: ["/bin/sh", "-c","env"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
打印
了解pause
Kubernetes 中所谓的 pause 容器有时候也称为 infra 容器,它与用户容器”捆绑“运行在同一个 Pod 中,最大的作用是维护 Pod 网络协议栈(当然,也包括其他工作,下文会介绍)。
都说 Pod 是 Kubernetes 设计的精髓,而 pause 容器则是 Pod 网络模型的精髓,理解 pause 容器能够更好地帮助我们理解 Kubernetes Pod 的设计初衷。为什么这么说呢?还得从 Pod 沙箱(Pod Sandbox)说起。
Pod Sandbox 与 pause 容器
创建 Pod 时 Kubelet 先调用 CRI 接口 RuntimeService.RunPodSandbox 来创建一个沙箱环境,为 Pod 设置网络(例如:分配 IP)等基础运行环境。当 Pod 沙箱(Pod Sandbox)建立起来后,Kubelet 就可以在里面创建用户容器。当到删除 Pod 时,Kubelet 会先移除 Pod Sandbox 然后再停止里面的所有容器。
从 Kubernetes 的底层容器运行时 CRI 看,Pod 这种在统一隔离环境里资源受限的一组容器,就叫 Sandbox。
Tips:一个隔离的应用运行时环境叫容器,一组共同被 Pod 约束的容器就叫 Pod Sandbox。她们同生共死,共享底层资源。 虚拟机与容器一样底层都使用 cgroups 做资源配额,而且概念上都抽离出一个隔离的运行时环境,只是区别在于资源隔离的实现。因此,从字面是上看,虚拟机和容器还是有机会都用沙箱这个概念来“套“的。事实上,提出 Pod 沙箱概念就是为 Kubernetes 兼容不同运行时环境(甚至包括虚拟机!)预留空间,让运行时根据各自的实现来创建不同的 Pod Sandbox。对于基于 hypervisor 的运行时(KVM,kata 等),Pod Sandbox 就是虚拟机。对于 Linux 容器,Pod Sandbox 就是 Linux Namespace(Network Namespace 等)。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Service对象隐藏了各Pod资源,并负责将客户端的请求流量调度至该组pod对象之上。不过,偶尔也会存在这样一类需求:客户端需要直接访问Service资源后端的所有pod资源,这时就应该向客户端暴露每个pod资源的IP地址,而不再是中间层Service对象的ClusterIP,这种类型的Service资源便称为Headless Service。
** Headless Service对象没有ClusterIP**,于是kube-proxy便无须处理此类请求,也就更没有了负载均衡或代理它的需要。在前端应用拥有自有的其他服务发现机制时,Headless Service即可省去定义ClusterIP的需求。至于如何为此类Service资源配置IP地址,则取决于它的标签选择器的定义。
具有标签选择器:端点控制器(Endpoints Controller)会在API中为其创建Endpoints记录,并将ClusterDNS服务中的A记录直接解析到此Service后端的各Pod对象的ip地址上。
没有标签选择器:端点控制器不会在API中为其创建Endpoints记录,ClusterDNS的配置分为两种情形:对ExternalName类型的服务创建CNAME记录,对其他三种类型来说,为那些与当前Service共享名称的所有Endpoints对象创建一条记录。
1. 创建Headless Service资源
配置Service资源配置清单时,只需要将ClusterIP字段的值设置为None,即可将其定义为Headless类型.
如下示例:
[root@k8s-master1 service]# cat headless-svc.yaml
kind: Service
apiVersion: v1
metadata:
name: my-nginx-headless-svc
spec:
clusterIP: None
ports:
- protocol: TCP
port: 80
targetPort: 80
name: httpport
selector:
run: my-nginx
[root@k8s-master1 service]# kubectl apply -f headless-svc.yaml
service/my-nginx-headless-svc created
[root@k8s-master1 service]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 44d <none>
my-nginx-headless-svc ClusterIP None <none> 80/TCP 9s run=my-nginx
使用资源创建命令完成资源创建后,查看获取的Service资源相关信息便可看到,它没有ClusterIP,不过如果标签选择器能够匹配到相关的pod资源,它便拥有EndPoints记录,这些EndPoints对象会作为DNS资源记录名称my-nginx-headless-svc查询时的A记录解析结果。
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # by default is 1
minReadySeconds: 10 # by default is 0
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: registry.k8s.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
使用场景 当我们需要进行服务端认证,甚至双向认证时,我们需要生成密钥对和服务信息,并使用ca对公钥和服务信息进行批准签发,生成一个证书。
我们简单描述下单向认证和双向认证的场景流程
在单向认证场景中:
服务端会将自己的证书和公钥告知客户端 客户端向CA查询该证书的合法性,确认合法后会记录服务端公钥 客户端会与服务端明文通信确认加密方式, 客户端确认加密方式后,会生成随机码作为对称加密密钥,以服务端的公钥对对称加密密钥进行加密,告知服务端, 服务端以自己的私钥解密得到对称加密密钥, 之后, 客户端与服务端之间使用对称加密密钥进行加密通信。 在双向认证的场景中:
服务端会将自己的证书和公钥告知客户端 客户端向CA查询该证书的合法性,确认合法后会记录服务端公钥 客户端会将自己的证书和公钥发给服务端, 服务端发现客户端的证书也可以通过CA认证,则服务端会记录客户端的公钥 然后客户端会与服务端明文通信确认加密方式, 但服务端会用客户端的公钥将加密方式进行加密 客户端使用自己的私钥解密得到加密方式,会生成随机码作为对称加密密钥,以服务端的公钥对对称加密密钥进行加密,告知服务端, 服务端以自己的私钥解密得到对称加密密钥, 之后, 客户端与服务端之间使用对称加密密钥进行加密通信。 那么,我们如果要开放自己的https服务,或者给kubelet创建可用的客户端证书,就需要:
生成密钥对 生成使用方的信息 使用ca对使用方的公钥和其他信息进行审核,签发,生成一个使用方证书。 这里使用方可以是客户端(kubelet)或服务端(比如一个我们自己开发的webhook server)
手动签发证书 k8s集群部署时会自动生成一个CA(证书认证机构),当然这个CA是我们自动生成的,并不具有任何合法性。k8s还提供了一套api,用于对用户自主创建的证书进行认证签发。
准备 安装k8s集群 安装cfssl工具,从这里下载cfssl和cfssljson 创建你的证书 执行下面的命令,生成server.csr和server-key.pem。
cat <<EOF | cfssl genkey - | cfssljson -bare server
{
"hosts": [
"my-svc.my-namespace.svc.cluster.local",
"my-pod.my-namespace.pod.cluster.local",
"192.0.2.24",
"10.0.34.2"
],
"CN": "kubernetes",
"key": {
"algo": "ecdsa",
"size": 256
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
这里你可以修改文件里的内容,主要是:
基础原则
- 每个Pod都拥有一个独立的IP地址,而且假定所有Pod都在一个可以直接连通的、扁平的网络空间中,不管是否运行在同一Node上都可以通过Pod的IP来访问。
- 对于支持主机网络的平台,其Pod若采用主机网络方式,则Pod仍然可以不通过NAT的方式访问其余的Pod
- k8s中Pod的IP是最小粒度IP。同一个Pod内所有的容器共享一个网络堆栈,该模型称为IP-per-Pod模型。
- Pod由docker0实际分配的IP,Pod内部看到的IP地址和端口与外部保持一致。同一个Pod内的不同容器共享网络,可以通过localhost来访问对方的端口,类似同一个VM内的不同进程。
- IP-per-Pod模型从端口分配、域名解析、服务发现、负载均衡、应用配置等角度看,Pod可以看作是一台独立的VM或物理机。
Kubernetes网络地址4大关注点
- Pod内的容器可以通过loopback口通信
- 集群网络为Pods间的通信提供条件
- Service API暴露集群中的Pod的应用给外部,以便外部使用
- 也可只使用Services在集群内部使用